NodeListオブジェクトを取得できるメソッドには、getElementsByName()とquerySelector()、querySelectorAll()があります。ものの解説では、getElementByID()を筆頭にgetElement(s)ByXXXXXX系の方がqueriSelector(All)系より処理が早いそうです。まあ確かに、queriSelector(All)系に媒介変数として渡すセレクタ表記をみると、ちょっと遅そうな感じがします。
まずは、getElementsByName(‘値’)を使ってname属性(アトリビュート)の’値’が同じウェブページの要素(エレメント)を参照して取得してみます。いつものように環境はmacOS上のSafariです。
> e = document.getElementsByName('QuotationMark')
< NodeList (3) = $1
0 <input type="radio" name="QuotationMark" value="DQut" checked>
1 <input type="radio" name="QuotationMark" value="SQut">
2 <input type="radio" name="QuotationMark" value="None">
> e.constructor
< function NodeList() {[native code]}
> e instanceof Array
< false
> e[0].constructor
< function HTMLInputElement() {[native code]}
> e[0] instanceof Element
< true
NodeListオブジェクトはノードの集合でです。このノード(Node)ですが、ここではウェブページの要素オブジェクトすなわちエレメント(Element)オブジェクトのことです。ノードの方が概念が広いくらいの理解でよいと思います。XMLを扱うときはページ上に展開するモノという感覚はないので、自然とノードという表現になると思います。
getElementsByClassName()で取得された配列風HTMLCollectionオブジェクトについては前回投稿しました。このNodeListオブジェクトは、そこで参照できるHTMLElementインターフェースオブジェクトのchildNodesプロパティからも取得できます。わかり辛いですよね。でも実際は、HTMLCollectionオブジェクトと雰囲気はあまり変わりません。その確認です。
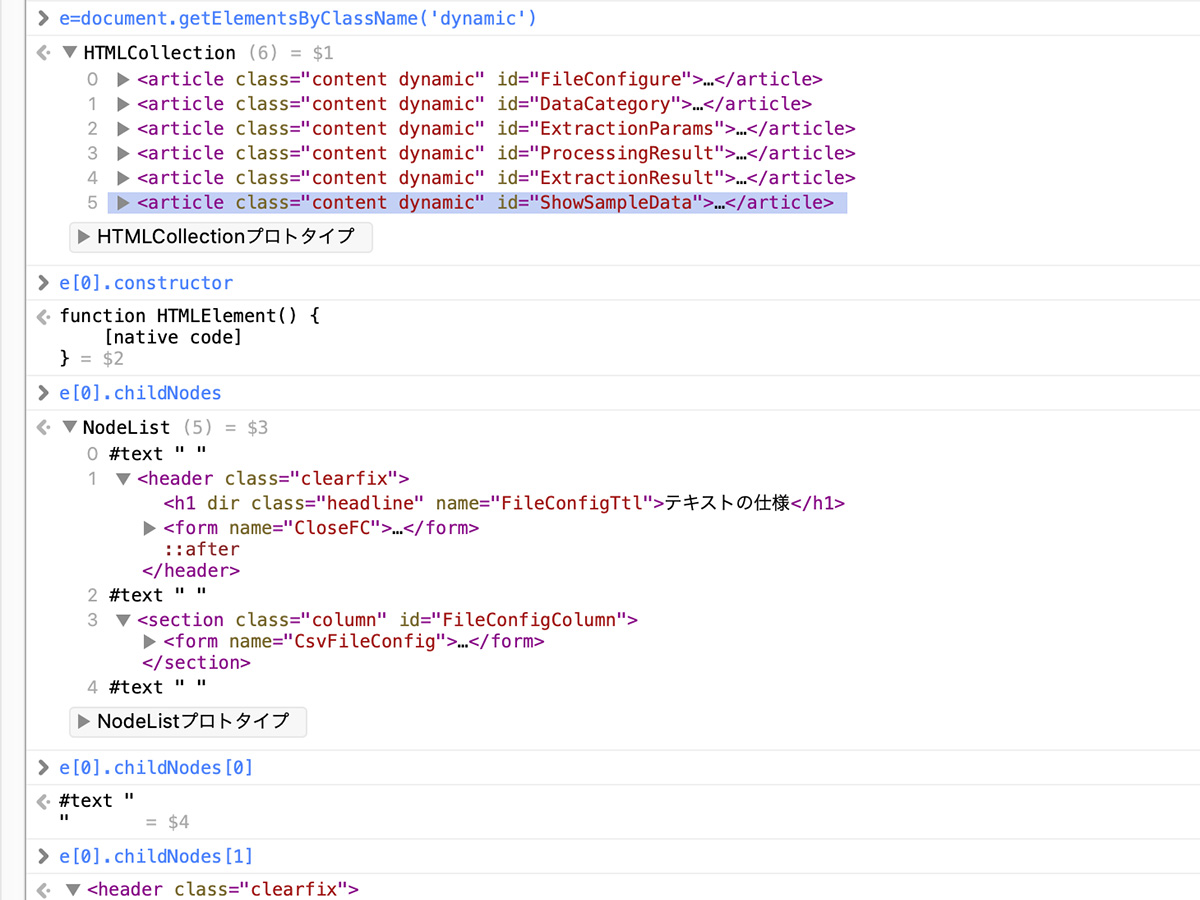
> e=document.getElementsByClassName('dynamic')
< HTMLCollection (6) = $1
0 <article class="content dynamic" id="FileConfigure">…</article>
1 <article class="content dynamic" id="DataCategory">…</article>
2 <article class="content dynamic" id="ExtractionParams">…</article>
3 <article class="content dynamic" id="ProcessingResult">…</article>
4 <article class="content dynamic" id="ExtractionResult">…</article>
5 <article class="content dynamic" id="ShowSampleData">…</article>
> e[0].constructor
< function HTMLElement() {[native code]}
それで、HTMLCollectionオブジェクトのchildNodesプロパティを参照するとNodeListオブジェクトが取得できます。
> e[0].childNodes < NodeList (5) = $3 0 #text " " 1 <header class="clearfix">…</header> 2 #text " " 3 <section class="column" id="FileConfigColumn">…</section> 4 #text " "
ということです。「#text ” “」は今のところゴミのようなものと考えて良いです。
> e[0].childNodes[1].constructor
< function HTMLElement() {[native code]}
> e[0].childNodes[1] instanceof Element
< true
というわけで、やっぱりエレメントオブジェクトが取得できて、他の取得方法同様に動的な運用ができるのできます。(でもご安心を!期待通りにイレギュラーは多々発生しますので退屈をすることはありません。すばらしい冒険と苦難を味わえます。)
それで、こっからが注目なのですが、メソッドの系統が変わるのでここで一回切ります。
次回は同じくNodeListオブジェクトを取得できるquerySelector()とquerySelectorAll()について取り上げます。
長らくJavaScriptを扱っていると、以前だと対応するブラウザがなくて全く利用を考えずにアウトオブ眼中ですっかり忘れていたものが、しっかり使えるようになっていることがあります。querySelectorAll()もそのひとつです。そんなものに出くわすと「おいら、何してたの?」とガッカリしてしまいます。音信不通であった友人が亡くなっていた時の感覚に似てます。ああ、自分もいい歳になっっちゃったんですね。そかさ。