本シリーズその3はgetElementsByName()を使うとNodeListオブジェクトが参照されて、やっぱり、エレメント(Element)オブジェクトが取得できるという話題でした。
今回も似たように参照と取得ができるquerySelector()とquerySelectorAll()を取り上げます。これらは、パラメータ(Parameter)の記述がスタイルシートのセレクタ(Selector)であるという特徴があります。
パラメーターは日本語では「 #媒介変数 」と言われるようですが、関数側で受け取るとアーギュメント(Argument)と呼ばれ同じく「 #引数 (ひきすう)」と言われています。ちょっと判別しにくいので「引いた数」に対して「渡す数」として、個人的には「 #渡し数 」とか「 #渡数 (とすう)」と呼んでます。おっと、閑話休題。
私が、これらqueriSelector系のメソッドを使うようになったのはここ最近です。記憶があやふやなのですが、以前は利用できる環境が限られた(のか?)などして利用対象から外れてしまっていたようです。最近になって、 #名前空間 の参照利用を調べていたところ、今は?利用できることに気がついての次第です。(ちょっとした衝撃でした。)
ものの解説によると、getElementXXXXXX系と比較して処理が遅いとのことです。(いっちゃん早いのはgetElementById()だそうです。)
それではまずquerySelectorAll(‘セレクタ’)の方から紹介します。いつものようにmacOS上でSafariもしくはGoogle Chromでのコンソール出力の表記です。また、「>」後がコンソールへ打ち込んだ入力テキストで、「<」後がリターンキーを押すと現れる出力情報です。
> q = document.querySelectorAll('p')
< NodeList (5) = $5
0 <p dir class="lead" name="PageTitleLead">…</p>
1 <p dir class="lead" name="AppLead">…</p>
2 <p dir class="attention" name="FileRecommendation">…</p>
3 <p dir class="lead" name="footlineLead">…</p>
4 <p>…</p>
> q.constructor
< function NodeList() {[native code]}
> q instanceof Array
< false
> q.length
< 5
> q[0].constructor
< function HTMLParagraphElement() {[native code]}
> q[0] instanceof Element
< true
ウェブページ内のPタグをNodeListオブジェクトにて参照できました。配列風のNodeListオブジェクトであること、でも配列(Array)オブジェクトではないこと、だけども配列長(Length)は参照できることを確認してます。それで最初のオブジェクト要素(インデックス0番)のコンストラクタ(Constructor)を確認して、且つ、エレメントオブジェクト由来のインスタンス(Instance)であることを確認してます。
前回のgetElementsByName()と同じですね。でもパラメータはあくまでもCSSのセレクタの記述として解釈されてるようです。ですから…、
> q = document.querySelectorAll('p[name="PageTitleLead"]')
< NodeList (1) = $11
0 <p dir class="lead" name="PageTitleLead">…</p>
> q = document.querySelectorAll('body p.lead')
< NodeList (3) = $13
0 <p dir class="lead" name="PageTitleLead"> … </p>
1 <p dir class="lead" name="AppLead">…</p>
2 <p dir class="lead" name="footlineLead">…</p>
「p[name=”PageTitleLead”]」や「body p.lead」といったまるまるCSSのセレクタの記述方式で参照ができます。
これはちょっと探すのに手間取って、遅いと言われるのも感覚的にうなずけそう…。
まあこの程度なら、無理に使わなくてもgetElementXXXXXX系で事足りるのではないかと思われますよね?以前の私もその様に理解したのかもしれません。
でも、前述しました様にqueriSelector系の利用に至ったのは、どうしてもXMLを比較的高度に運用する必要があり、名前空間の学習をしていたことにあります。
実際にgetElementXXXXXX系とqueriSelector系では名前空間の参照に違いがあります。それが名前空間の運用に影響するかは、これからの検証とアプリケーション設計にあり、まだ説明できる程度にありません。よって、ここではページエレメントの運用について私個人がquerySelectorAll(‘セレクタ’)を利用している例を紹介します。
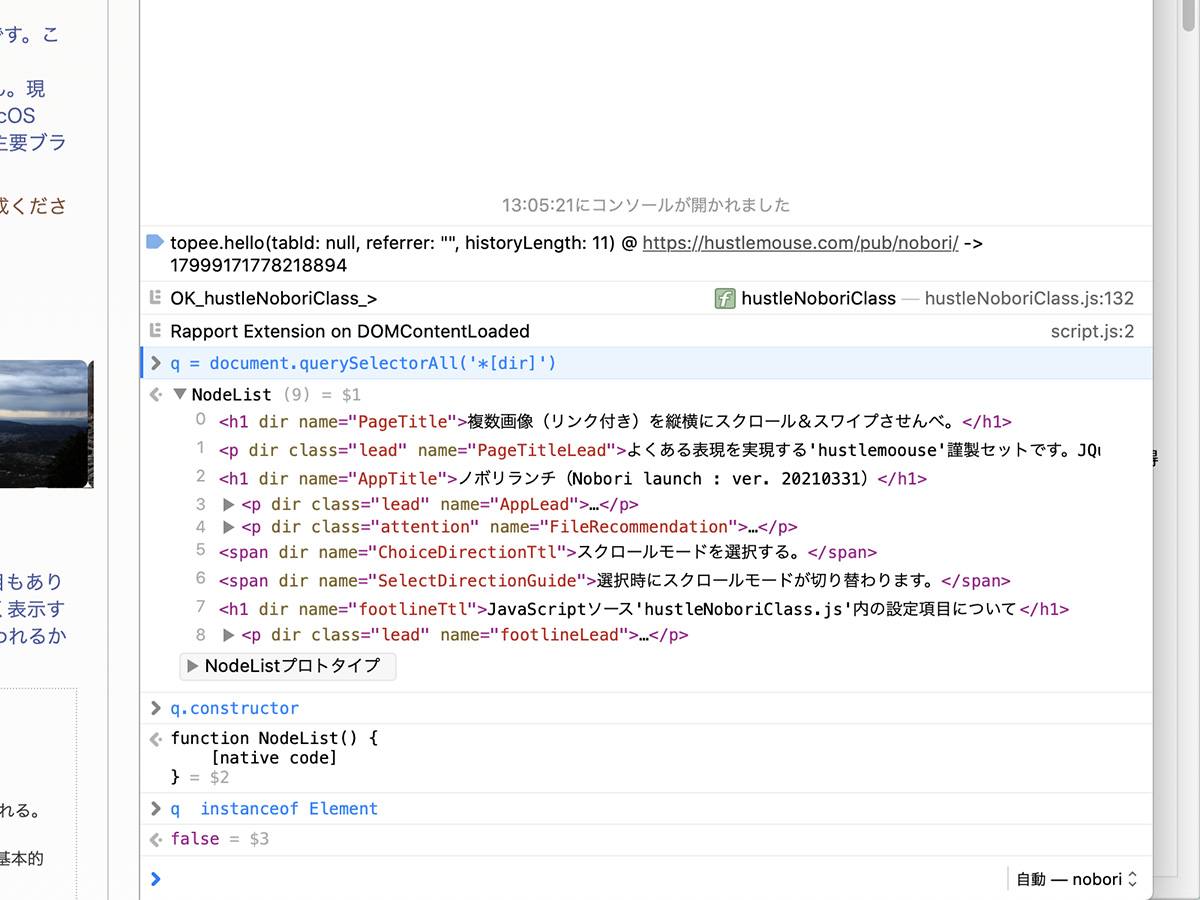
> q = document.querySelectorAll('*[dir]')
< NodeList (9) = $14
0 <h1 dir name="PageTitle">…</h1>
1 <p dir class="lead" name="PageTitleLead">…</p>
2 <h1 dir name="AppTitle">…</h1>
3 <p dir class="lead" name="AppLead">…</p>
4 <p dir class="attention" name="FileRecommendation">…</p>
5 <span dir name="ChoiceDirectionTtl">…</span>
6 <span dir name="SelectDirectionGuide">…</span>
7 <h1 dir name="footlineTtl">…</h1>
8 <p dir class="lead" name="footlineLead">…</p>
ウェブページ内のすべてのエレメントを対象にdir属性のあるエレメントのNodeListオブジェクトを取得して、ページコンテンツの言語をごっそりと変更するのに利用してます。
dir属性は文章の書字方向を指定するものです。たとえばアラビア語への対応なんて考えてもいないのですが、文章の入ったエレメントにdir属性をつけておくのは比較的に自然に感じたので、これを条件にリストを取得する手配をとっています。私のケースでした。
最後になりますが、querySelector(‘セレクタ’)です。
> q = document.querySelector('p')
< <p dir class="lead" name="PageTitleLead">…</p>
> q.constructor
< function HTMLParagraphElement() {[native code]}
> q instanceof Element
< true
パラメータのセレクタ表記は同じです。querySelectorAll()と異なるのは、同条件のエレメントをリストしてくれるのではなく、ページの中で条件を最初に満たしたエレメントオブジェクトを直に返すことです。コンストラクタとインスタンスを確認しておきました。
これはHTMLとCSSのコーディング計画の如何によって効果的に利用が可能だと思いますが、今のところid属性の参照ぐらいにしか思いつきません。「それは最速のgetElementById()と被るなあ。」という感想ですが、比較的に構成がシンプルになるXMLでは利用できそうです。
これでページエレメント取得シリーズについては終了です。概ね把握できたのではないかと期待します。(私に見落としのあるやもしれませんが…。おっと、getElementsByTagNameNS()は名前空間で…、)
この勢いで、HTMLやXMLの名前空間を参照して運用するための学習をすすめ、その成果?を後日投稿できたらと思ってます。そかさ。